
python正则表达式
[toc]
python正则表达式
常用正则表达式操作符
| 操作符 | 说明 | 实例 | ||
|---|---|---|---|---|
| . | 表示任何单个字符 | |||
| [] | 字符集,对单个字符给出取值范围 | [abc]表示a、b、c,[a-z]表示a到z的单个字符 | ||
| 非字符集,对单个字符给出排除范围 | abc表示非a或b或c的单个字符 | |||
| * | 前一个字符的0次或无穷次扩展 | abc*表示ab、abc、abcc、abccc等 | ||
| + | 前一个字符的1次或无限次扩展 | abc+表示abc、abcc、abccc等 | ||
| ? | 前一个字符的0次或1次扩展 | abc?表示ab、abc | ||
| \ | 左右表达式各一个 | abc\ | def表示abc、def | |
| {m} | 扩展前一个字符m次 | ab{2}c表示abbc | ||
| {m,n} | 扩展前一个字符m至n次(含n) | ab{1,2}c表示abc、abbc | ||
| ^ | 匹配字符串开头 | ^abc表示abc且在一个字符串的开头 | ||
| $ | 匹配字符串结尾 | abc$表示abc且在一个字符串的结尾 | ||
| () | 分组标记,内部只能使用\ | 操作符 | (abc)表示abc,(abcldef)表示abc、def | |
| \d | 数字,等价于[0-9] | |||
| \w | 单词字符,等价于[A-Za-z0-9_] |
经典正则表达式实例
匹配首尾空白字符的正则表达式:^s|s$
匹配Email地址的正则表达式:w+([-+.]w+)@w+([-.]w+).w+([-.]w+)
匹配网址URL的正则表达式:[a-zA-z]+://[^s]
匹配帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$
匹配国内电话号码:d{3}-d{8}|d{4}-d{7}, 匹配形式如 0511-4405222 或 021-87888822 920-209 642-964
匹配腾讯qq号:^[1-9][0-9]{4,10}$, 从五位数开始匹配,也就是 10000
匹配中国邮政编码:[1-9]d{5}(?!d), 中国邮政编码为6位数字
匹配身份证:d{15}|d{18},评注:中国的身份证为15位或18位
匹配ip地址:d+.d+.d+.d+, 评注:提取ip地址时有用
贪婪模式与非贪婪模式
贪婪模式(Greedy)
在正则中,表示次数的量词默认是贪婪的,在贪婪模式下,会尝试尽可能最大长度去匹配
字符串 aaabb 中使用正则 a* 的匹配过程

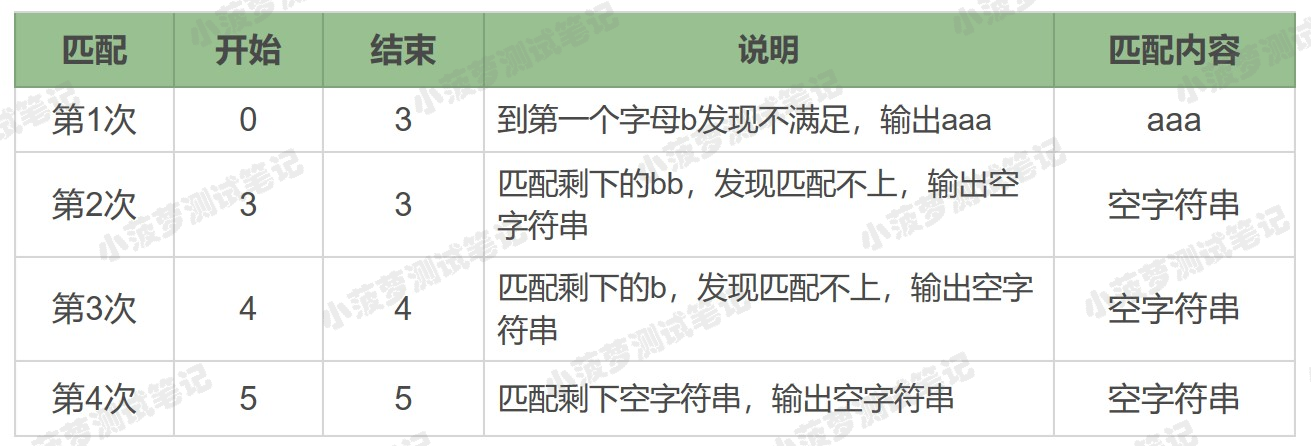
分析
a* 在匹配开头的 a 时,会尽量匹配更多的 a,直到第一个 b 不满足要求为止,匹配上三个 a,后面每次匹配时都得到空字符串
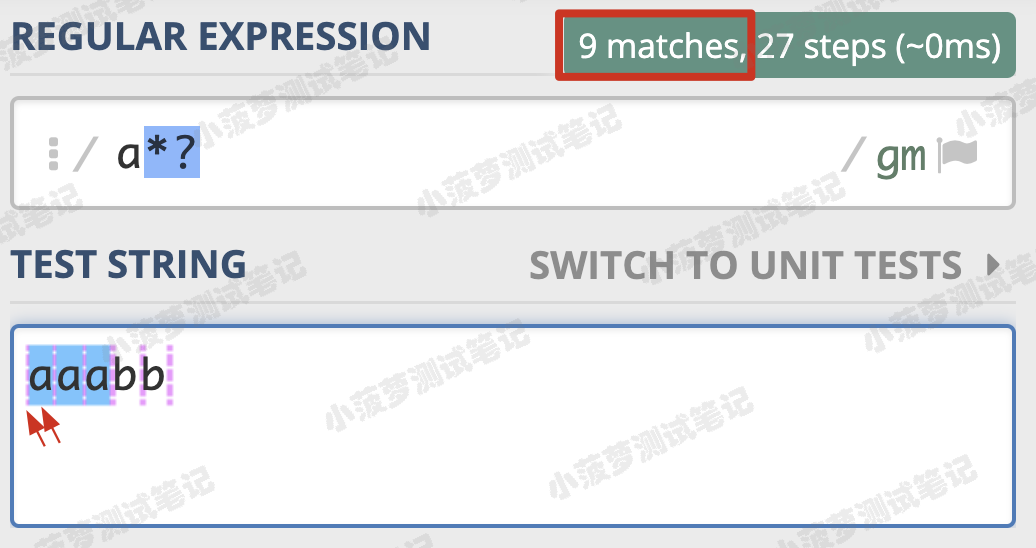
非贪婪匹配(Lazy)
如何从贪婪模式变成非贪婪模式呢
在量词后面加上 ? ,正则就变成了 a*?
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 小chen妙妙屋!
相关推荐




评论