
汇编语言
1 汇编语言基础
1.1 寄存器
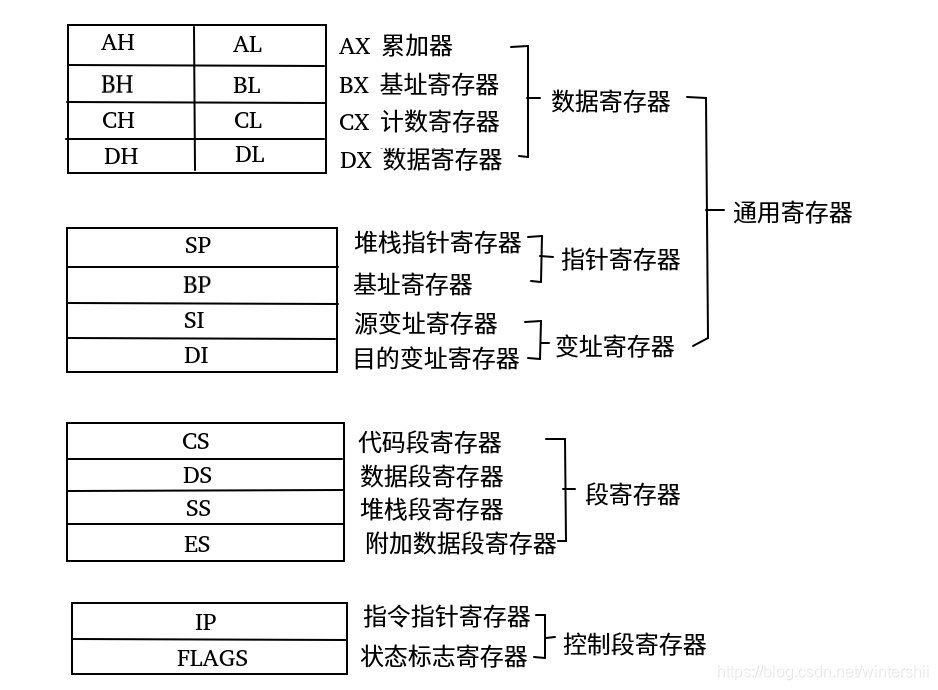
1.1.1 64位通用寄存器
分类:rax\rbx\rcx\rdx\rdi\rsi\r8-r15
作用:主要作为算数运算、暂存数据以及传递参数,其中rax\rbx\rcx\rdx\rdi是基础通用寄存器、rdi\rsi\r8-r15是扩展寄存器 当调用函数时,前6个参数通常不会放在栈上,而是直接塞进指定的寄存器中,传递顺序:rdi>rsi>rdx>rcx>r8>r9
1.1.2 指令指针寄存器
作用:指向下一条将要执行的机器指令的地址
pwn的最终目的就是为了劫持rip,控制了rip,就可以按照想要的方式进行
1.2 简单 X64 汇编
CPU 内部寄存器之间的数据传送:1
2
3mov AL, DH; AL <- DH (8位)
mov DX, AX; DX <- AX (16位)
mov RAX, RSI; RAX <- RSI (64位) ; 原 32 位为 mov EAX, ESI
CPU 内部寄存器和存储器之间的数据传送:
1 | mov [BX], AX; 间接寻址 (16位) |
立即数送通用寄存器、存储器:
1 | mov RAX, 1234567890ABCDEFH; RAX <- 1234567890ABCDEFH (64位) ; 原 32 位为 mov EAX, 12345678H |
1.2.1 算数指令
ADD / SUB / INC / DEC / MUL / DIV / AND / OR / XOR / NOT
1.2.2 CMP 比较指令
cmp 指令是实现逻辑判断的核心。cmp 指令通过对两个操作数进行减法操作,仅记录标志位(Flag)信息,不保存计算结果。
- OF (Overflow Flag) 溢出标志。溢出时为 1,否则置 0。
- SF (Sign Flag) 符号标志。结果为负时置 1,否则置 0。
- ZF (Zero Flag) 零标志。运算结果为 0 时 ZF 位置 1,否则置 0。
- CF (Carry Flag) 进位标志。进位时置 1,否则置 0。
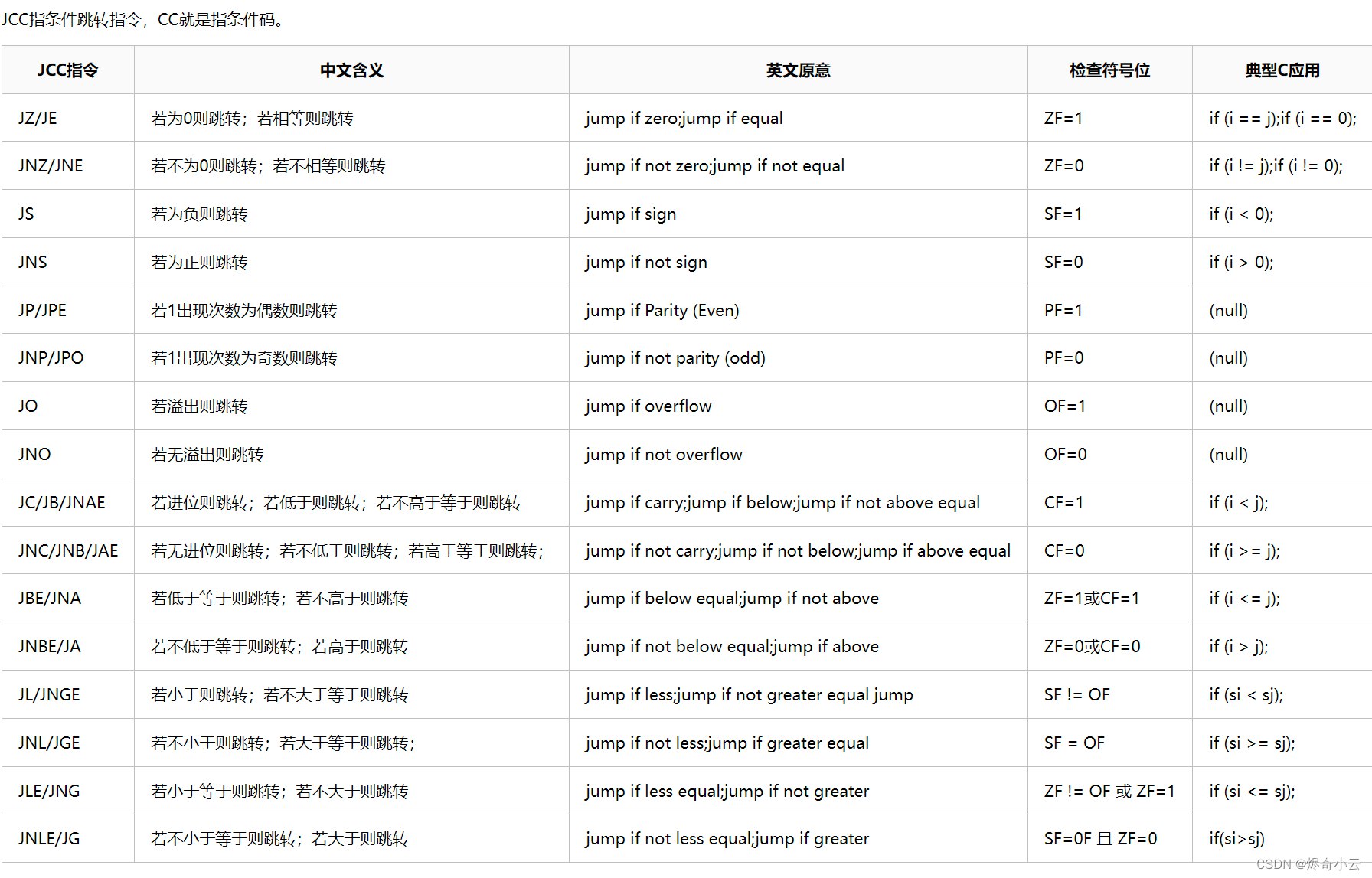
1.2.3 跳转指令 (JCC)
1.3 堆
作用:用于动态分配内存,当我们在程序中使用malloc、calloc、realloc等函数时,分配的内存就来自于堆;当使用free函数时,就是释放堆上的内存
比如char *p=malloc(100);,这句话的意思是从堆上分配100个字符,然后把内存赋值给p 核心特性:堆的地址是由低向高生长的,也就是说,第一次分配堆的内存地址较低,后续不断分配堆内存时,地址会越来越高
1.4 栈
1.4.1 基础
栈是我们做PWN时的一个十分重要的数据结构,栈区也是一个需要注意的内存区域
栈是一种数据结构,存放局部变量,从感性上说,可以想象成羽毛球筒,球只能从筒口插入,从筒口拿出
栈是由高地址向低地址生长
1.4.2 操作
栈具有push和pop两种操作,分别叫入栈与出栈
1 | push rax |
1.4.3 栈帧
进程中每个函数在运过程中都要保存自己的临时数据,这些数据就会被保存在栈上 但是不同的函数不能把数据放在一块。每个函数都要有自己的栈空间。系统给出的方案就是栈帧 栈帧指的就是一个函数在运行时使用的栈空间,它由rsp和rbp表示边界 rsp与rbp是CPU中的两个特殊寄存器,rsp叫栈顶指针寄存器,rbp叫栈底指针寄存器。两个寄存器专门用来表示stack范围
1.4.3.1 栈顶指针
作用:永远指向当前栈的“物理最顶部”(也就是栈的最后一个压入数据的地址)
栈的操作都会直接影响rsp的值
push操作:rsp会减少(因为栈地址是从高地址指向低地址,压入数据后,会向低地址移动)
pop操作:rsp会增加
1.4.3.2 栈底指针
作用:永远指着当前函数栈帧的底部 核心作用就是定位——程序找局部变量,找函数参数时,都是以rbp为参考的,比如代码buf[16],它在栈中的地址可能是rbp-0x10(rbp减去16字节),程序通过rbp的值,就能精确找到buf的地址
另外,rbp还会保存上一个函数栈帧的底部地址,这样函数执行结束后,程序能通过Saved RBP,找到上一个函数的栈帧,进而回到上一个函数继续执行
1.5 函数调用约定
调用约定规范了函数之间调用的方式、参数如何传递、返回值如何传递、栈由谁来平衡
比较常见的调用约定:
__cedcl- 又称为 C 调用约定,是C/C++ 语言缺省的调用约定。参数按照从右至左的方式入栈,函数本身不清理栈,此工作由调用者负责,返回值在RAX中。由于由调用者清理栈,所以允许可变参数函数存在,如
int sprintf(char* buffer,const char* format……)
- 又称为 C 调用约定,是C/C++ 语言缺省的调用约定。参数按照从右至左的方式入栈,函数本身不清理栈,此工作由调用者负责,返回值在RAX中。由于由调用者清理栈,所以允许可变参数函数存在,如
__stdcall- 很多时候被称为pascal调用约定。pascal语言是早期很常见的一种用于教学计算机程序设计语言,其语法严谨。参数从右至左的方式入栈。函数自身清理堆栈,返回值在RAX中
__fastcell- 特点就是快,是由CPU寄存器来传递参数,用RCX和RDX传递前两个四字(QWORD)或更小的参数,剩下的参数按照从右至左的方式入栈,函数自身清理堆栈,返回值在RAX中 一、 核心寄存器定义 在 x86_64 (64位) 函数调用体系中,有两个专门用于管理栈内存的寄存器:
RSP (Stack Pointer / 栈顶指针): 物理层面的指针。它永远指向当前栈空间的最顶部(最低内存地址处)。
RBP (Base Pointer / 栈底基址指针): 逻辑层面的指针。它指向当前正在执行的函数栈帧的固定基准线。
1.5.1 为什么不能只用 RSP?(引入 RBP 的根本原因)
在函数执行的过程中,程序经常需要计算临时数据,这会导致频繁的 push(压栈)和 pop(出栈)操作。
RSP 的缺陷(高度动态): 随着每一次压栈和出栈,RSP 的值都在实时跳动。如果编译器试图通过 RSP + 偏移量 来寻找参数或局部变量,由于 RSP 本身在不断变化,这个偏移量也必须实时重新计算,这在工程实现上是极其复杂且容易出错的。
RBP 的解法(绝对静止): 为了提供一个稳定的参照物,系统在进入函数之初,会将当时的栈顶状态“冻结”并保存在 RBP 中。在整个函数运行期间,RBP 的值固定不变。编译器只需使用固定的 RBP ± 偏移量,就能极其精准地定位所有数据。
1.5.2 栈帧的建立与销毁(标准汇编范式) 理解以下两段标准的汇编代码,是分析任何二进制程序的基石。
1.5.2.1 函数序言—— 建立当前函数的领地
当程序刚跳入一个新函数时,必定会执行以下指令:
1 | push rbp ; 1. 备份:将调用者(父函数)的 RBP 压入栈中保存(Saved RBP)。 |
1.5.2.2 函数结语—— 恢复现场并返回
当函数执行完毕,准备返回父函数时:
1 | mov rsp, rbp ; 1. 释放:将 RSP 降回 RBP 的位置,瞬间废弃所有局部变量。 |
1.5.2.3 RBP 静态坐标系速查表
| 内存位置 (基于 RBP) | 存放内容 | 说明 | 读写权限 / 危险性 |
|---|---|---|---|
[rbp + 0x18] |
参数 2 (Arg 2) | 从右向左压栈的第二个参数 | 正常读取 |
[rbp + 0x10] |
参数 1 (Arg 1) | 从右向左压栈的第一个参数 | 正常读取 |
[rbp + 0x08] |
返回地址 (Return Address) | 函数执行完后,下一条要执行的指令地址 | 极度危险!PWN 的核心目标 |
[rbp + 0x00] |
Saved RBP | 父函数的基址指针备份 | 危险,被覆盖会导致父函数栈崩溃 |
[rbp - 0x08] |
局部变量 1 | 函数内部声明的第一个变量 | 正常读写,溢出的源头 |
[rbp - 0x10] |
局部变量 2 | 函数内部声明的第二个变量 | 正常读写 |
1.6 检查操作
1.6.1 查看程序基本信息file
命令作用:查看程序的架构(32位/64位)、链接方式(动态链接/静态链接)、文件格式(ELF)等信息
实操执行:file demo

解读:
ELF 64-bit LSB executable:这是个64位的ELF可执行文件,运行在x86-64上dynamically linked:这是动态链接库,体积小,主要依赖于外部的系统库not stripped没有剥离符号表,包含了函数名、变量名等信息
1.6.2 检查保护机制checksec
1 | root@ubuntu-pwn:/learning# checksec demo |
结果解读:
CANARY- 金丝雀保护,金丝雀会生成随机值,程序执行时会放入栈帧中,栈溢出时会先覆盖掉金丝雀,会导致程序检测崩溃,关闭后才能自由覆盖返回地址
PIE- 地址随机化保护:开启后,程序地址
.text、.data、栈、堆等区域都会随机变化
- 地址随机化保护:开启后,程序地址
NX- Linux默认开启的保护机制,作用是让栈上的数据不能当成代码执行
RELRO- 作用是保护
.got表,阻止.got被篡改
- 作用是保护
1.6.3 查看依赖库ldd
命令作用:查看动态程序依赖的所有系统库
结果解读:
因为libc库里面有很多system函数,要调用函数,就必须知道它在内存中的地址
1.6.4 扫描程序中的文本strings
命令作用:快速扫描程序中所有可打印的纯文本字体
2 C语言基础
2.1 程序的编译与链接

2.2 可执行文件
- 广义:文件中的数据是可执行的文件
.out、.exe、.sh、.py
- 狭义:文件中的数据是机器码中的文件
- Windows:PE
- 可执行文件
.exe
- 动态链接库
.dll
- 静态链接库
.lib
- 可执行文件
- Linux:ELF
- 可执行文件
.out
- 动态链接库
.so
- 静态链接库
.a
- 可执行文件
3 Linux基础
- 保护层级:分为四个ring0-ring3
- 一般来说就两个,0和3
- 0为内核
- 3为用户
3.1 权限
用户可以分为多个组
文件和目录等的权限一般是三个,可读可写可执行
赋予一个可执行文件执行权限,就是chmod +x filename
3.1.1 段权限
代码段包含了代码与只读权限
- .text 节
- .rodata 节
- .hash 节
- .dynsym 节
- .dynstr 节
- .plt 节
- .rel.got 节
数据段包含了可读可写权限
- .data 节
- .dynamic 节
- .got 节
- .got.plt 节
- .bss 节
栈段
3.2 虚拟内存和物理内存
- 物理内存很直白,就是内存中实际的地址
- 虚拟内存是物理内存经过MMU转换后的地址(页表)
- 系统会给每个用户进程分配一段虚拟内存空间
所以说我们调试的可执行的程序的内存空间布局都差不多,但是虚拟内存,不是实际的物理内存
3.3 数据的存储方式
3.3.1 大端小端序
- 大端序:数据高位存储在计算机地址的低位,数据低位存储在地址的高位
- 大端序:数据高位存储在计算机地址的高位,数据低位存储在地址的低位
linux数据存储的格式为小端序
3.4 文件描述符
linux中,把一切都看作是文件,当进程打开现有文件或者创建新文件时,内核向进程返回一个文件描述符,文件描述符就是内核为了高效管理已被打开的文件所创建的索引,用来指向被打开的文件,所有执行I/O操作的系统调用都会通过文件描述符
每个文件描述符会与一个打开的文件相对应,不同的文件描述符也可能指向同一个文件
相同文件可以被不同的进程打开,也可以在同一个进程被多次打开
3.4.1 常见操作
我们会在open\read\write这些函数中见到文件描述符
0代表标准输入、1标准输出、2标准错误
read从stdin中读size个数据到buf中
write从buf中取size个数据到stdout中
3.5 ELF文件
3.5.1 结构
linux环境中,二进制可持文件的类型是ELF
elf文件格式比较简单,它的基础信息存在于elf的头部信息中,这些信息包括指令的运行框架、程序入口等等,可以通过readelf -h <elf_name>来查看头部信息
elf文件包含很多个节,每个节中存放着不同的数据,包括
| 名称 | 作用 |
|---|---|
| .text | 存放程序运行的代码 |
| .rdata | 存放一些如字符串等不可修改的数据 |
| .data | 存放已经初始化的可修改的数据 |
| .bss | 存放未被初始化的程序可修改的数据 |
| .plt与.got | 程序动态链接地址 |
3.5.1.1 ELF文件头表
- 记录ELF文件的组织结构
3.5.1.2 程序头表/段表
- 告诉程序如何创建进程
- 生成进程的可执行文件必须拥有此结构
- 重定位文件不一定需要
3.5.1.3 节头表
- 记录ELF文件的节区信息
- 用于链接的目标文件必须拥有此结构
- 其他类型的目标文件不一定需要
3.5.2 进程内存映像
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30【磁盘:ELF 文件 (基于 Section)】 【内存:进程镜像 (基于 Segment)】
+-------------------------------+ +-------------------------------+ 高地址
| ELF Header | | 内核空间 |
+-------------------------------+ +-------------------------------+
| Program Header Table (PHT) | | Stack (向下增长) |
+-------------------------------+ | | |
| .text (代码) | ==> PT_LOAD ==> v |
+-------------------------------+ | |
| .rodata (只读数据) | ==> PT_LOAD ==> | |
+-------------------------------+ | ^ |
| .data (初始化数据) | ==> PT_LOAD ==> | | |
+-------------------------------+ | Heap (向上增长) |
| (磁盘中不占空间的数据) | +-------------------------------+
+-------------------------------+ | Data Segment (R/W) |
| +---------------------------+ |
| | .bss (全0) | | <--- 自动生成
| +---------------------------+ |
| | .data | |
| +---------------------------+ |
+-------------------------------+
| Text Segment (R/X) |
| +---------------------------+ |
| | .rodata | |
| +---------------------------+ |
| | .text | |
| +---------------------------+ |
+-------------------------------+
| 不可访问区 |
+-------------------------------+ 0x00000000
3.6 动态链接库
我们程序开发中都会用到的函数,如read\write\open等
这些函数不需要我们实现,因为系统已经帮我们完成了这些工作,只需要调用就行,存放这些函数的库文件就是动态链接库
通常情况下,我们遇到最多的还是libc.so文件
3.6.1 libc
glibc是linux下c标准库的实现,即GNU C Library
glic本身是GNU旗下的C标准库,后面逐渐成了Linux的标准库,而linux下原本的C标准库逐渐不再维护
Linux下标准库不仅有一个,但最多的还是libc
glic在虚拟内存中可以存在多份,但在实际内存中只有一份
3.7 延迟绑定
在动态链接(Dynamic Linking)中,程序在装载时需要对外部函数和全局变量进行重定位。如果程序在启动时就强行解析并绑定所有调用的外部共享库函数(如 libc 中的 printf、system 等),会极大地拖慢程序的启动速度,尤其是在实际上很多函数在一次运行中可能根本不会被执行到的情况下。
为了解决这个“运行效率不高、浪费资源”的问题,ELF 引入了延迟绑定(Lazy Binding)机制:只有当函数第一次被真正调用时,才去解析它的实际物理地址并进行绑定。
为了实现延迟绑定,ELF 文件依赖两个核心的数据结构:GOT 表和PLT 表。
3.7.1 GOT 表
GOT 表位于数据段 (Data Segment) 中,是用来保存在地址无关代码(PIC, Position-Independent Code)中确定的全局变量和外部函数绝对地址的表。由于它在数据段,因此在程序运行时通常是可读可写的。
在 ELF 文件中,GOT 表被细分为了两个主要部分:
.got表:用于保存全局变量的引用地址。在程序加载时,动态链接器会直接解析并填充这里的地址。.got.plt表:用于保存外部函数引用的真实物理地址。这就是延迟绑定的核心阵地。对于每个需要调用的外部函数,在这个表中都会有一项。- 前三项的特殊用途:
GOT[0]:包含.dynamic段的地址,动态链接器用来提取动态链接相关信息。GOT[1]:包含当前本模块(也就是当前的 ELF 文件)的 ID 信息。GOT[2]:包含动态链接器中解析函数地址的代码入口,即_dl_runtime_resolve()的地址。
- 前三项的特殊用途:
3.7.2 PLT 表
PLT 表位于代码段 中,因此它是只读的。它本质上是一小段一小段的跳板代码(Stub),程序对外部函数的调用,实际上都是先跳到 PLT 表中对应的跳板代码,再由跳板代码决定下一步的走向。
PLT 表的结构通常如下:
PLT[0](公共桩):这是一段特殊的代码,负责跳转到动态链接器去执行符号解析。它会访问GOT[1]和GOT[2]。PLT[1]...PLT[n](函数跳板):每一个外部函数(如printf)都有一个对应的 PLT 桩(例如printf@plt)。
3.7.3 延迟绑定的完整执行流程
以调用 printf 为例,理解“第一次调用”和“后续调用”的区别是掌握延迟绑定的关键:
3.7.3.1 第一次调用外部函数:
- 调用发生:程序代码执行
call printf@plt,跳转到 PLT 表中printf对应的代码桩。 - 首次跳转:
printf@plt的第一条指令是jmp *(printf@got.plt)。由于是第一次调用,此时printf@got.plt中存储的并不是printf的真实地址,而是指向了printf@plt中的下一条指令。 - 准备解析:于是程序没有跳走,而是顺着 PLT 继续往下执行,将
printf在重定位表中的索引(ID)压入栈中(push index)。 - 跳转公共桩:接着跳转到
PLT[0]。 - 执行解析:
PLT[0]将本模块的 ID(GOT[1])压栈,并跳转到GOT[2]中存储的动态链接器解析函数_dl_runtime_resolve()。 - 回填地址与执行:
_dl_runtime_resolve()根据传入的索引,在共享库中找到真实的printf地址,将真实地址写入到printf@got.plt中(这就是绑定的过程),最后直接跳转去执行真实的printf函数。
3.7.3.2 第二次及以后的调用:
- 程序再次执行
call printf@plt。 - 再次执行第一条指令
jmp *(printf@got.plt)。 - 此时,
printf@got.plt里面存储的已经是上一步回填的printf真实地址。 - 程序直接跳转到真实的
printf函数执行,不再经过压栈和_dl_runtime_resolve()解析的过程。



