
逆向-汇编代码基础
基础元素
1 | move eax,5;将5传输至eax保存 |
整数常量
0A3h 十六进制
42q 八进制
26d 十进制
01010101b 二进制
操作数的类型
立即数
立即数就是写在指令里的常数。还是用mov操作举例子,mov 12, %rax,那么这个 12 就在操作语句里。那么 12 相当于指令里的立即数。
寄存器操作数
参加运算的数存放在指令给出的寄存器中,可以是16位或8位。例如“mov AX 8080H”就是要将8080H拷贝至寄存器AX中,但是AX在这里是数据存放目标地址的代名词。
- 通用寄存器:
EAX,EBX,ECX,EDX(用于常规数据运算与暂存)。 - 指针/变址寄存器:
ESP,EBP,ESI,EDI(用于栈操作与内存寻址)。 - 标志寄存器: **
EFLAGS - 指令指针寄存器:
EIP(存储下一条将要执行的指令地址)。
通用寄存器

EAX寄存器,EAX的低16位AX寄存器,AX的高8位AH寄存器和低8位AL寄存器。
EBX寄存器,BX寄存器,BH寄存器,BL寄存器。
ECX寄存器,CX寄存器,CH寄存器,CL寄存器。
EDX寄存器,DX寄存器,DH寄存器,DL寄存器。
ESI寄存器,ESI的低16位SI寄存器。
EDI寄存器,EDI的低16位DI寄存器。
EBP寄存器,EBP的低16位BP寄存器。
ESP寄存器,ESP的低16位SP寄存器。
标志寄存器
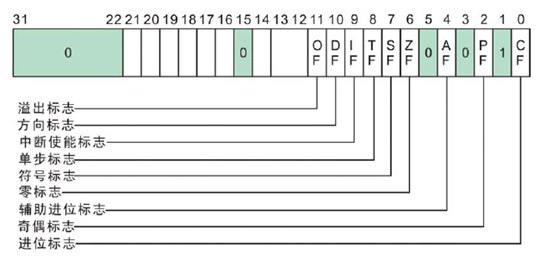
OF(Overflow Flag)
溢出标志 ,用于表示算术运算是否产生溢出。
溢出标志OF用于反映有符号数加减运算所得结果是否溢出。如果运算结果超过当前运算位数所能表示的范围,则称为溢出,OF的值被置为1,否则,OF的值被清为0。
无符号,进位看CF
有符号,进位看OF
有无符号是自定义的

DF(Direction Flag)
方向标志 ,控制串操作指令的方向。
IF(Interrupt Enable Flag)
中断使能标志 ,用于控制可屏蔽中断的使能与禁止。
TF(Trap Flag):单步标志 ,用于设置单步调试模式。
SF(Sign Flag):符号标志 ,反映算术运算结果的符号。
ZF(Zero Flag):零标志 ,表示运算结果是否为零。
AF(Auxiliary Carry Flag):辅助进位标志 ,主要用于 BCD 码算术运算中辅助进位检测。
PF(Parity Flag):奇偶标志 ,反映运算结果中 “1” 的个数的奇偶性。
CF(Carry Flag):进位标志 ,用于表示无符号数算术运算中的进位或借位情况。
内存操作数
内存操作数(Memory Operand)是汇编指令中指向计算机主存(RAM)地址的数据引用
在汇编中是[]括号内的计算结果,它是一个内存地址,去该地址读取或写入数据,而不是直接使用这个数值本身。
硬指令
汇编传输指令
mov指令
MOV指令,能实现以下操作:
CPU内部寄存器之间数据的任意传送(除了码段寄存器CS和指令指针IP以外)。
立即数传送至CPU内部的通用寄存器组(即AX、BX、CX、DX、BP、SP、SI、DI),给这些寄存器赋初值。
CPU内部寄存器(除了CS和IP以外)与存储器(所有寻址方式)之间的数据传送,可以实现一个字节或一个字的传送。
能实现用立即数给存储单元赋初值。
扩展指令
movzx(Move with Zero-Extend - 零扩展):- 机制: 将源数据放入目标寄存器的低位,目标寄存器剩余的高位全部硬性填充为 0。
- C 语言映射: 无符号类型之间的向上转换。例如
unsigned char转换为unsigned int或int。
movsx(Move with Sign-Extend - 符号扩展):- 机制: 将源数据放入目标寄存器的低位,目标寄存器剩余的高位根据源数据的最高位(符号位)进行填充。如果源数据最高位是 1(负数),高位全填 1;如果是 0(正数),高位全填 0,以此保证扩展前后数值的符号和大小不变。
- C 语言映射: 有符号类型之间的向上转换。例如
char转换为int。
LAHF指令
用于将标志寄存器的低八位送入AH,即将标志寄存器FLAGS中的SF、ZF、AF、PF、CF五个标志位分别传送到累加器AH的对应位,八位中有三位是无效的;
SAHF指令
SAHF(保存 AH 内容到状态标志位)指令将 AH 内容复制到 EFLAGS(或 RFLAGS)寄存器低字节。例如,可以检索之前保存到变量中的标志位数值:
XCHG指令
XCHG 指令用于交换两个操作数的内容,它是 mov 指令的简化版。XCHG 指令的操作数格式与 mov 指令相同,但不能使用立即数作为操作数。
算术运算指令
add指令
ADD指令的基本格式是_ADD DST, SRC_,其中DST是目标操作数,SRC是源操作数。DST和SRC不能同时为存储器,DST不能为立即数。例如,以下是一些使用ADD指令的示例:
1 | ADD AX, BX ; 将AX和BX寄存器的值相加,结果存储在AX中 |
sub指令
直接减数字:
1 | SUB AL, 5 → 把AL寄存器里的值减5(8位) |
变量/内存减数字:
1 | SUB [num], 10 → 把内存里叫num的变量减10 |
寄存器互减:1
2
3SUB AX, BX → AX = AX - BX
SUB CL, DL → CL = CL - DL
也可以反过来:SUB EAX, [num] → 用EAX减内存里的值
inc指令
指令用于将寄存器或内存中的操作数加 1,而不影响进位标志(CF)
dec指令
DEC指令用于将操作数减1,同时不影响进位标志CF,但会更新其他状态标志位。
伪指令
offset指令
它的核心作用是在汇编阶段获取变量或标号(Label)在其所在段内的相对偏移地址。
在 x86 架构的内存寻址模型中,物理地址的定位通常由“段基址(Segment Base)”和“偏移地址(Offset Address)”两部分共同完成:
- 段基址:定义了内存段的起始物理位置。
- 偏移地址:定义了具体数据或指令相对于该段首地址的线性距离。
offset 操作符的作用正是提取这一段内距离。当汇编器(Assembler)扫描源代码并遇到 offset 标识符 时,它会计算出该标识符相对于其所在数据段或代码段起始位置的字节偏移量。随后,汇编器会将这个计算出的数值作为一个常量立即数,直接硬编码到最终生成的机器码指令中。
ptr指令
为什么需要 ptr?(消除宽度歧义)
当 CPU 访问内存时,它必须同时明确两个物理要素:
- 基址(Base Address):从内存的哪个位置开始读写。
- 长度(Size/Width):连续读写多少个字节。
在很多指令中,汇编器可以通过寄存器的宽度来隐式推断内存操作的长度。例如: mov eax, [ebx] 因为 eax 是一个 32 位(4 字节)寄存器,汇编器会自动知道需要从 ebx 指向的内存地址处连续读取 4 个字节。此时不需要 ptr。
但在某些场景下,汇编器会陷入 “宽度歧义” ,最典型的就是将立即数(常量)直接写入内存: mov [ebx], 1 这条指令在编译阶段会报错。因为汇编器不知道这个 1 应该作为 1 个字节(01)、2 个字节(00 01)还是 4 个字节(00 00 00 01)写入目标内存。这时就必须通过 ptr 强制干预。
标准的 ptr 宽度规范
在逆向分析和底层开发中,你会频繁接触到以下几种标准的宽度定义符:
BYTE PTR:按 8 位(1 字节)操作。WORD PTR:按 16 位(2 字节)操作。DWORD PTR:按 32 位(4 字节)操作(Double Word)。QWORD PTR:按 64 位(8 字节)操作(Quad Word,在 x64 架构下常用)。
type指令
在 MASM/TASM 汇编体系中,type 与之前提到的 offset 和 ptr 一样,都是伪操作符(Pseudo-operator)。它在汇编(编译)阶段由汇编器进行静态求值,本身绝不会生成任何直接对应的机器码指令。
1. 核心定义与作用
type 操作符的核心作用是:返回变量或标号(Label)在定义时所占据的物理字节数(Byte Size),或者返回代码标号的调用类型标识值。
你可以将其等价理解为 C/C++ 语言中针对基本数据类型的 sizeof() 运算符在汇编层的静态映射。
2. 标准返回值对照
当汇编器在源代码中扫描到 type 加上一个已定义的变量名时,会根据该变量的数据宽度,将其在编译期直接替换为一个常量立即数:
db(Define Byte) 返回值:1dw(Define Word) 返回值:2dd(Define Double Word) 返回值:4dq(Define Quad Word) 返回值:8
lengthof指令
sizeof指令
跳转指令
jmp指令
一、 核心定义
jmp(Jump)指令是 x86 汇编中最基础的无条件转移指令。 它的核心作用是强制改变 CPU 的执行流。在微观物理层面上,执行 jmp 指令本质上就是通过硬件电路强制修改 CPU 内部的指令指针寄存器(IP/EIP/RIP),有时还会连同代码段寄存器(CS)一起修改,从而让 CPU 去新的内存地址取指执行,而不再按顺序执行下一条紧邻的指令。
二、 底层执行原理
流水线刷新 (Pipeline Flush): 现代 CPU 具有指令预取和流水线(Pipeline)机制。当译码器遇到
jmp指令时,CPU 意识到即将发生跳转,此前预取到流水线中的后续顺序指令将全部作废(Flush),这在微体系结构中被称为“分支惩罚(Branch Penalty)”。目标地址计算: CPU 的地址生成单元(AGU)根据指令中携带的操作数(相对偏移量或绝对地址),计算出真实的目标物理/虚拟地址。
寄存器覆写: 将计算出的目标地址覆写到
IP(段内转移)或CS:IP(段间转移)寄存器中。重新取指: CPU 的总线接口单元(BIU)根据新的
CS:IP指向的地址,重新向主存发起取指请求,程序流完成跳转。
三、 寻址机制与转移类型
jmp 指令根据修改的寄存器范围和跳转距离,严格划分为以下两大类、三种具体形态:
1. 段内转移
原理: 目标代码与当前 jmp 指令处于同一个代码段内。因此,只需要修改 IP 寄存器的值,CS(代码段寄存器)保持不变。 根据 IP 修改的跨度(位移量),又细分为:
段内短转移 (Short Jump)
语法:
jmp short 标号机器码特征: 操作码
EB+ 8位相对位移量 (disp8)。位移范围:
-128 ~ 127字节。地址计算公式:
新 IP = 当前 IP + 8位位移量(注意:此处的“当前 IP”是指 CPU 已经读取完这句jmp指令后,指向的下一条指令的首地址)。位移量以补码形式存放,最高位为符号位,决定向前(负跳)还是向后(正跳)。
段内近转移 (Near Jump)
语法:
jmp near ptr 标号机器码特征: 操作码
E9+ 16位或32位相对位移量 (disp16或disp32)。位移范围: * 在 16 位实模式下:
-32768 ~ 32767字节。- 在 32 位保护模式下:可以覆盖整个 4GB 线性地址空间。
地址计算公式:
新 IP = 当前 IP + 16/32位位移量。
2. 段间转移
原理: 目标代码与当前 jmp 指令不在同一个代码段。这就要求必须同时修改 CS(代码段寄存器)和 IP(指令指针寄存器)。
段间远转移 (Far Jump)
语法:
jmp far ptr 标号机制: 标号不仅包含目标地址的偏移量,还隐式包含了目标地址所在的段基址。
地址执行细节: CPU 会用标号所在段的段地址覆盖当前的
CS寄存器,用标号在段内的偏移地址覆盖当前的IP寄存器。注:在 32/64 位操作系统的保护模式下,Far Jump 的机制变得更为复杂,通常涉及段描述符表(GDT/LDT)、特权级检查(如通过调用门 Call Gate 实现 Ring 3 到 Ring 0 的切换),而不仅是简单的数值替换。
loop指令
这是一份为您量身定制的、具有深度专业视角的 loop(循环控制)指令解析笔记。在微体系结构的层面上,loop 指令的设计哲学与 jmp 有着显著的不同,它是一种高度复合(Compound)的指令。
一、 核心定义
loop 指令是 x86 架构中专门用于控制已知循环次数的精简指令。
从汇编语法上看,它只需要一个操作数(即跳转的目标标号)。但从底层微架构的视角来看,它隐式地(Implicitly)绑定了 CPU 的计数寄存器(CX / ECX / RCX,取决于工作模式)。它将“计数器递减”和“条件跳转”这两个动作浓缩在了一个机器码周期内。
二、 底层执行原理与微架构动作
当 CPU 的指令译码器遇到 loop 标号 指令时,会在内部将其拆解为以下微操作(Micro-operations, µops)序列:
隐式递减 (Implicit Decrement): CPU 的算术逻辑单元(ALU)自动将计数寄存器(在 16 位下是
CX,32 位下是ECX)的值减去 1。即执行内部等效的ECX = ECX - 1。零值探测 (Zero Detection): CPU 检查递减后的计数寄存器的值是否等于 0。
条件分支 (Conditional Branch):
如果不为 0 (
ECX ≠ 0): CPU 的地址生成单元(AGU)计算标号的地址,并将其覆写进指令指针寄存器(IP/EIP),程序流跳转回循环体的开头。如果为 0 (
ECX = 0): 循环结束。CPU 不做任何跳转操作,直接按顺序向下执行loop指令紧挨着的下一条指令。
⚠️ 核心专业细节(与 DEC + JNZ 的本质区别):
通常开发者会认为 loop label 等价于 dec ecx 加上 jnz label。在逻辑结果上确实如此,但在微观状态上有一个致命区别:
执行
dec ecx会修改标志寄存器(EFLAGS)的状态(如 ZF, SF, OF 等)。执行
loop指令递减计数器时,绝不会影响任何 EFLAGS 标志位。这种设计允许在循环体内部进行复杂的带进位/借位运算(如adc,sbb),而不必担心loop指令会破坏运算产生的标志位。
三、 指令寻址机制与物理限制
与 jmp 指令拥有多种跳转距离不同,loop 指令在物理设计上被严格限制为段内短转移 (Short Jump)。
机器码特征: 操作码
E2+ 8位相对位移量 (disp8)。位移范围: 目标标号所在的地址,必须在当前
loop指令下一条指令地址的 -128 到 +127 字节范围内。工程意义: 这种设计强迫编译器或汇编程序员将循环体控制在较小的代码块内,这非常契合 CPU 一级指令缓存(L1i Cache)的局部性原理(Locality of Reference),有助于提高缓存命中率。
四、 LOOP 指令族扩展
除了基础的无条件计数循环,x86 指令集还提供了结合标志位状态的复杂循环指令。它们不仅检查 ECX 是否为 0,还额外检查零标志位(ZF)的状态:
| 指令语法 | 别名 | 执行条件(必须同时满足两项,否则退出循环) | 典型应用场景 |
|---|---|---|---|
loope 标号 |
loopz |
1. ECX = ECX - 1 ≠ 02. ZF = 1 (上一次运算结果为零/相等) |
在数组中查找第一个不等于某值的元素。 |
loopne 标号 |
loopnz |
1. ECX = ECX - 1 ≠ 02. ZF = 0 (上一次运算结果非零/不相等) |
在字符串或数组中查找第一个等于某特定字符/数值的元素。 |
五、 现代微体系结构视角的性能考量
虽然 loop 指令在汇编代码的视觉上非常简洁优雅(用一条指令代替了两条指令),但在现代超标量(Superscalar)和具备复杂分支预测(Branch Prediction)的 CPU 上(如 Intel Core 架构、AMD Zen 架构):
loop指令的执行往往比拆分开的dec ecx配合jnz label更慢。原因: 现代 CPU 的解码器更擅长将简单的 RISC 风格指令(如
dec和jnz)进行宏指令融合(Macro-op Fusion)并高效塞入乱序执行(Out-of-Order Execution)流水线。而像loop这样带有复杂历史包袱的复合 CISC 指令,反而需要被分解成微代码(Microcode)序列执行,消耗更多时钟周期。编译器行为: 因此,现代的 C/C++ 编译器(如 GCC, Clang, MSVC)在开启优化(-O2, -O3)后,几乎绝不会生成
loop指令,而是清一色地使用dec/sub配合条件跳转指令来实现for或while循环。
寻址方式
在计算机体系结构和汇编语言中,寻址方式(Addressing Modes)是指微处理器在执行指令时寻找操作数(Operand)物理地址的机制。理解不同的寻址方式是掌握底层内存管理、数据结构访问以及指令执行效率的关键。
1. 立即寻址方式
概念定义:
在立即寻址中,操作数本身作为指令的一部分直接编码在机器码中,紧跟在操作码(Opcode)之后。它主要用于为寄存器或内存位置赋初值。
代码解析:
1 | mov eax, 11 ; 立即数 11 直接存入 eax |
专业特点:
执行效率极高: CPU在取指阶段(Instruction Fetch)就直接获取了操作数,无需额外的内存读取周期(Memory Read Cycle)。
局限性: 只能作为源操作数(Source Operand),不能作为目的操作数(Destination Operand,因为立即数没有内存地址可供写入)。
2. 寄存器寻址方式
概念定义:
指令指定的寄存器中存放着所需的操作数。CPU 直接在内部寄存器堆(Register File)中进行读写操作。
代码解析:
1 | mov ebx, 0x36d ; 源操作数为立即寻址,目的操作数为寄存器寻址 |
专业特点:
速度最快: 寄存器位于 CPU 内部,访问延迟在所有存储层级中最低。
资源受限: CPU 内的通用寄存器(GPRs)数量有限(如 x86 架构下的 EAX, EBX, ECX, EDX 等),编译器需要通过寄存器分配算法(Register Allocation)进行优化调度。
3. 直接寻址方式
概念定义:
指令中直接包含了操作数所在的内存有效地址(Effective Address, EA)。通常表现为一个变量名或标号(Label)。
代码解析:
1 | mov ecx, msg ; 将标号 msg 所代表的内存绝对地址(或偏移地址)装入 ecx |
注:在某些汇编器(如 NASM)中,msg 表示地址本身;而在 MASM 中,通常使用 OFFSET msg 获取地址,直接写 msg 可能会被解析为读取该地址的内容 [msg]。此处代码的逻辑是获取地址,为后续的指针操作做准备。
专业特点:
确定性强: 内存地址在编译或链接阶段就已经固定(硬编码)。
适用场景: 常用于访问全局变量或静态数据区。
4. 寄存器间接寻址方式
概念定义:
操作数的有效地址存放在某个特定的通用寄存器中。CPU 首先读取寄存器的内容,将其作为指针(Pointer),然后去访问该指针指向的物理内存。
代码解析:
1 | mov esi, msg ; 将内存地址存入变址寄存器 esi |
专业特点:
- 动态灵活性: 允许在程序运行期间动态修改寄存器中的地址,是实现指针操作、字符串遍历的核心机制。
5. 寄存器相对寻址方式
概念定义:
操作数的有效地址是基址寄存器或变址寄存器的内容,加上指令中指定的一个常数偏移量(Displacement)。
代码解析:
1 | mov ecx, msg ; 基址准备 |
专业特点:
- 数据结构访问: 这是访问结构体(Struct)成员或类对象的标准模式。寄存器指向结构体的首地址,偏移量对应结构体内特定成员的字节位置。
6. 基址变址寻址方式
概念定义:
有效地址由一个基址寄存器(Base Register)的值,加上一个变址寄存器(Index Register)的值乘以比例因子(Scale Factor,通常为 1、2、4 或 8)组合而成。
代码解析:
1 | mov ecx, msg ; ecx 作为基址寄存器 |
专业特点:
- 数组遍历的利器: 极其适合访问一维数组。
ecx存储数组首地址,edx作为数组下标(Index),*2表示数组元素的大小为 2 字节(例如 16-bit 的 Word 类型)。
7. 相对基址变址寻址方式
概念定义:
这是 x86 架构中最复杂的寻址方式,结合了前面几种模式。有效地址等于:基址寄存器 + (变址寄存器 × 比例因子) + 常数偏移量。
代码解析:
1 | mov ecx, msg ; 基址 |
专业特点:
- 高阶数据结构映射: 专门用于处理复杂的数据结构,例如二维数组、包含数组的结构体、或者栈帧(Stack Frame)中局部变量与参数的复杂定位。这种寻址方式利用了 CPU 内部的地址计算单元(AGU, Address Generation Unit),能在单条指令周期内完成复杂的指针算术运算,极大地优化了执行效率。