
汇编代码原理
理论
物理组件无法解释或理解高级语言,因为它们实际上只能处理 1 和 0 这样的二进制数据。这就是汇编语言发挥作用的地方,它是一种低级语言,能够直接编写处理器可以理解的指令。
由于处理器只能处理二进制数据,即 1 和 0 这样的二进制代码,因此对于人类来说,如果不参考手册来知道哪个十六进制代码对应哪个指令,那么与处理器进行交互就会变得非常困难。
这就是为什么会开发出低级别的汇编语言。通过使用汇编语言,开发者可以编写出人类能够理解的机器指令,这些指令随后会被转化为与机器代码相当的形式,从而让处理器能够直接执行它们。因此,有些人将汇编语言称为“符号化机器代码”。例如,汇编代码“ add rax, 1 ”比对应的机器壳代码“ 4883C001 ”更易于理解和记忆,也比相应的二进制机器代码“ 01001000 10000011 11000000 00000001 ”更易于记住。正如我们所看到的,如果没有汇编语言,要编写机器指令或直接与处理器交互将会非常困难。
机器码通常表示为 Shellcode ,即机器码字节的十六进制表示形式。壳码可以转换为相应的汇编代码,并且也可以作为二进制指令直接加载到内存中以便执行。
高级语言与低级语言
由于存在不同的处理器设计,每种处理器都理解不同的机器指令集和不同的汇编语言。在过去,应用程序必须针对每种处理器分别编写成汇编代码,因此要开发适用于多款处理器的应用程序并不容易。到了 20 世纪 70 年代初,人们开发了高级编程语言(如 C ),使得可以编写一种易于理解的代码,这种代码可以在任何处理器上运行,而无需为每种处理器重新编写代码。具体来说,这是通过为每种语言开发相应的编译器来实现的。
编译型语言
当高级代码被编译时,它会被转化为适用于特定处理器的汇编指令。之后,这些汇编指令还会被组装成机器代码,以便在处理器上运行。这就是为什么会有针对不同语言和不同处理器的编译器,它们能够将高级代码转化为与相应处理器兼容的汇编代码和机器代码
解释性语言
后来,人们开发了解释型语言,比如 Python 、 PHP 、 Bash 、 JavaScript 等。这些语言通常不会被编译,而是在运行时被解释执行的。这类语言利用预构建的库来运行指令。这些库通常是用其他高级语言如 C 或 C++ 编写的,然后被编译成可执行文件。因此,当我们使用解释型语言发出一个命令时,它会调用已编译的库来执行该命令,而该库则通过汇编代码或机器代码来执行命令所需的全部操作。
计算机架构
如今,大多数现代计算机都是基于所谓的冯·诺伊曼架构设计的。这一架构是由 Von Neumann 在 1945 年提出的,其目的是创造出“通用计算机”。 Alan Turing 在当时的描述中提到,冯·诺伊曼架构的灵感来源于 Charles Babbage 在 19 世纪中叶提出的“可编程计算机”概念。需要注意的是,所有这些人的背景都是数学家。
这种架构通过执行机器代码来实现特定算法的运行。它主要由以下几个组件构成:
- 中央处理单元
- 控制单元
- 算数/逻辑单元
- 寄存器
- 内存
- I/O存储
- 输入/输出设备
- 大容量存储单元
内存
计算机的内存是用来存储当前运行中的程序的数据和指令的地方。计算机的内存器也被称为主存储器。它是 CPU 获取和处理数据的主要场所。由于 CPU 需要频繁地访问存储器(每秒数十亿次),因此存储器和访问器的速度必须非常快。
有两个:缓存和随机存储器,一般人们生活中说的内存都是随机存储器(RAM)
缓存
缓存存在于CPU内部,相比于RAM速度快得多,运行频率和CPU一致
由于 RAM 的时钟频率通常远低于 CPU 核心的时钟频率,而且 RAM 也远离 CPU 的位置,因此如果 CPU 需要等待 RAM 来执行每条指令,那么 CPU 的实际运行频率就会大大降低。这正是缓存内存的主要优势所在。它使得 CPU 能够比从 RAM 中读取指令和数据更快地处理即将执行的指令。
根据缓存内存与 CPU 核心的接近程度,通常可以分为三个级别:
| Level 级别 | Description 描述 |
|---|---|
Level 1 Cache |
通常以千字节为单位表示,这是最快速的内存资源,位于每个 CPU 核心中。(只有一些寄存器具有更快的访问速度。) |
Level 2 Cache |
通常以兆字节为单位表示大小,速度非常快(但比 L1 层次要慢一些)。这些缓存专属于每个 CPU 核心使用。它们充当 L1 和 L3 之间的中间层。 |
Level 3 Cache |
通常以兆字节为单位表示大小(比 L2 更大)。速度比 RAM 快,但比 L1/L2 慢。(并非所有 CPU 都使用 L3 缓存。) |
RAM
RAM 的容量远大于缓存内存,其大小可以从吉字节到太字节不等。此外,RAM 位于距离 CPU 核心较远的位置,因此其访问速度比缓存内存要慢得多。从 RAM 中读取数据需要执行更多的指令。
在过去,由于使用的是 32 位地址空间,内存地址的范围被限制在 0x00000000 到 0xffffffff 之间。这意味着最大可使用的 RAM 大小为 2 32 字节,也就是大约 4 吉字节。而一旦达到这个限制,我们就无法再分配新的地址了。现在,由于使用了 64 位地址空间,地址范围扩大到了 0xffffffffffffffff ,理论上最大的 RAM 使用规模可以达到 $2^{64}$ 字节,即大约 18.5 艾字节(1800 万太字节)。因此,我们不应该很快面临内存地址不足的问题。
当程序运行时,所有的数据和指令都会从存储单元转移到 RAM 中,这样 CPU 在需要时可以随时访问这些数据。之所以要这样做,是因为从存储单元访问数据的速度要慢得多,这会延长数据处理的时间。而当程序结束时,程序中的数据会被从 RAM 中移除,或者可以被重新使用。
RAM 被划分为四个主要的部分 segments 。
| Segment 片段/部分 | Description 描述 |
|---|---|
Stack |
该系统采用后进先出的设计思路,且规模固定不变。其中的数据只能通过特定的顺序进行访问,即需要不断向内部添加或移除数据。 |
Heap |
这种数据结构具有层次结构,因此其在存储数据方面具有更大的灵活性和更高的效率,因为数据可以以任意顺序进行存储和检索。不过,这也使得这种数据结构比栈慢一些。 |
Data |
它包含两部分: Data ,用于存储变量; .bss ,用于存放尚未分配的变量(即,作为后续分配用的缓冲内存)。 |
Text |
主要的组装指令被加载到这个段中,之后由 CPU 进行提取和执行。 |
虽然这种分区方式适用于整个 RAM 空间,但 每个应用程序在运行的时候都有属于它自己的虚拟内存。这意味着每个应用程序都会拥有自己的 stack 、 heap 、 data 和 text 等段。
IO/存储
最后,还有输入/输出设备,比如键盘、屏幕,以及长期存储单元,也被称为辅助存储器。处理器可以通过 Bus Interfaces 来访问和控制这些输入输出设备,这些设备就像“高速公路”一样,用于传输数据和地址,其中二进制数据是通过电荷来处理的。
每个总线能够同时承载一定数量的位(或电荷)。通常,这个数量是以 4 位为间隔的倍数,最高可达 128 位。总线接口也常用于访问内存以及 CPU 之外的其他组件。如果我们仔细观察 CPU 或主板的构造,就会发现它们身上到处都存在着总线接口。
与易失性的主存储器不同,主存储器在程序运行期间只存储临时数据及指令,而存储单元则用于存储永久性的数据,比如操作系统文件或整个应用程序及其相关数据。
存储单元是访问速度最慢的部件。首先,因为它们距离 CPU 最远,所以通过 SATA 或 USB 等总线接口来访问它们时,数据存储和获取的时间会更长。此外,它们的设计也限制了能够存储的数据量。只要需要处理的数据量越大,存储单元的速度就会越慢。
CPU架构
中央处理单元(CPU)是计算机内部的主要处理单元。CPU 中包含负责数据移动和控制的 Control Unit 单元,以及负责根据程序指令执行各种算术和逻辑运算的 Arithmetic/Logic Unit 单元。
CPU 处理指令的效率和方式取决于其指令集(ISA)。行业内有多种不同的指令集,每种指令集都有自己处理数据的独特方式。 RISC 架构适用于处理较为简单的指令,这需要更多的周期,但每个周期的时间较短,所需功耗也较低。而 CISC 架构则适用于处理更复杂的指令,虽然处理这些指令需要较少的周期,但每个指令的处理时间更长,所需功耗也更大。
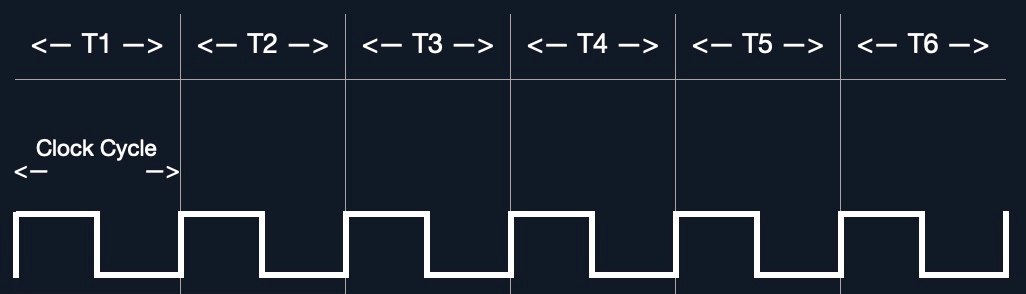
时钟频率与时钟周期
每个 CPU 都有一个时钟频率,这个频率决定了其整体运行速度。时钟的每次跳动代表一个时钟周期,这个周期用于执行一些基本指令,比如获取地址或存储地址。具体来说,这些操作是由 CPU 的算术逻辑单元来完成的。
这些周期发生的频率指的是每秒发生的周期数( Hertz )。例如,如果一个 CPU 的时钟频率为 3.0 吉赫,那么每个核心每秒可以执行 30 亿个周期。
指令周期
一个 Instruction Cycle 指的是 CPU 处理一条机器指令所需的周期数。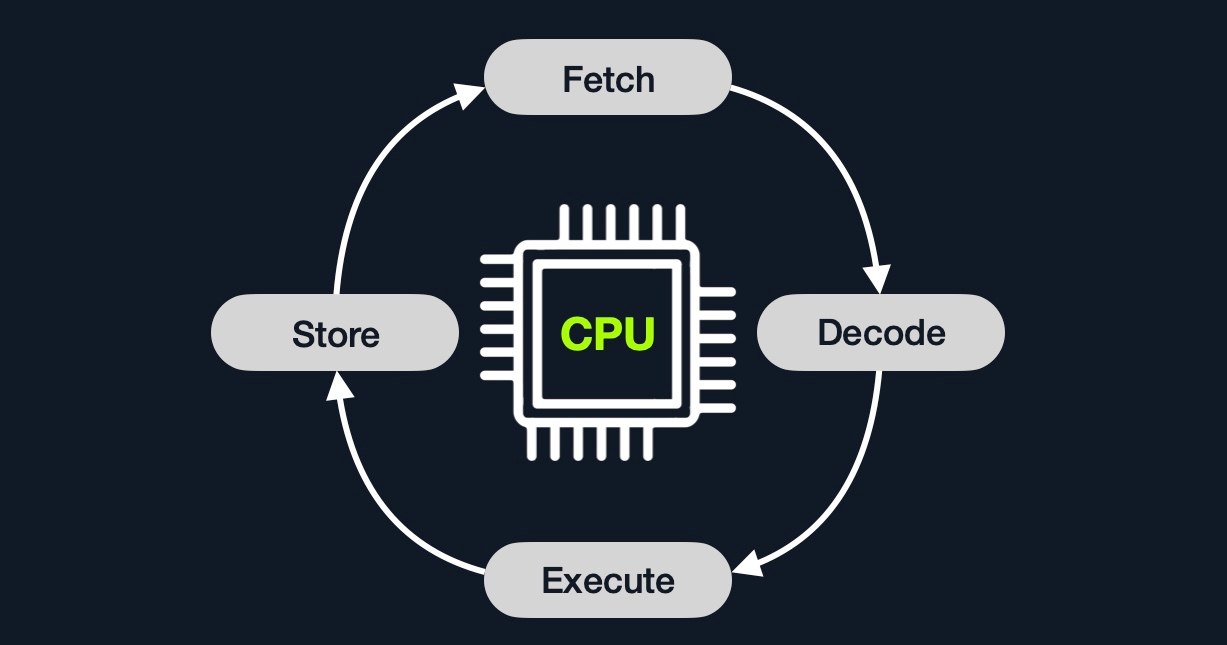
一个指令周期包括四个阶段: Fetch 、 Decode 、 Execute 和 Store 。
| Instruction 指导/指示 | Description 描述 |
|---|---|
1. Fetch |
从 Instruction Address Register (IAR)获取下一个指令的地址,这样就能知道下一个指令位于何处。 |
2. Decode |
根据 IAR 的指令,将二进制数据解码,以了解需要执行哪些操作。 |
3. Execute |
从寄存器/内存中获取指令操作数,然后处理 ALU 或 CU 中的指令。 |
4. Store |
将新值存储到目标操作数中。 |
在过去,处理器通常按顺序处理指令,因此必须等待一个指令完成后再开始下一个指令的处理。而现代处理器能够同时处理多个指令,因为它们具有多个指令/时钟周期,可以并行处理指令。这一能力的实现得益于其多线程和多核设计。
指令集架构
Instruction Set Architecture ( ISA )规定了每种架构上汇编语言的语法和语义。它不仅仅是一种不同的语法结构,而是深深融入了处理器的核心设计中,因为它影响着指令的执行方式、执行顺序以及指令的复杂程度。 ISA 主要由以下组件构成:
- Instructions 指示/说明
- Registers 寄存器
- Memory Addresses 内存地址
- Data Types 数据类型
寄存器、地址与数据类型
现在我们已经了解了计算机和处理器的基本架构,接下来需要掌握一些汇编语言的相关知识,这样才能开始学习汇编编程: Registers 、 Memory Addresses 、 Address Endianness 和 Data Types 。这些元素中的每一个都很重要,正确理解它们将有助于我们在编写和调试汇编代码时避免各种问题,以及节省大量时间和精力。
寄存器
如前所述,每个 CPU 核心都拥有一组寄存器。这些寄存器是计算机中速度最快的组件,因为它们直接集成在 CPU 核心内部。不过,寄存器的容量非常有限,每次只能存储几字节的数据。在 x86 架构中,存在许多寄存器,但我们将只关注那些对于学习基础汇编语言以及未来二进制系统利用至关重要的寄存器。
我们将重点关注两种类型的寄存器: Data Registers 和 Pointer Registers 。
| Data Registers 数据寄存器 | Pointer Registers 指针寄存器 |
|---|---|
rax |
rbp |
rbx |
rsp |
rcx |
rip |
rdx |
|
r8 |
|
r9 |
|
r10 |
Data Registers通常用于存储指令或系统调用参数。主要的数据寄存器包括:rax、rbx、rcx和rdx。rdi和rsi寄存器也存在,通常用于存储指令destination和source的操作数。此外,还有额外的数据寄存器,当所有前面的寄存器都被占用时,可以使用这些寄存器,它们分别是r8、r9和r10。Pointer Registers和rbp用于存储一些重要的地址指针。主要的指针寄存器包括:基址堆栈指针rbp,它指向堆栈的起始位置;当前堆栈指针rsp,它指向堆栈中的当前位置(即堆栈的顶部);还有指令指针rip,它保存下一个指令的地址。
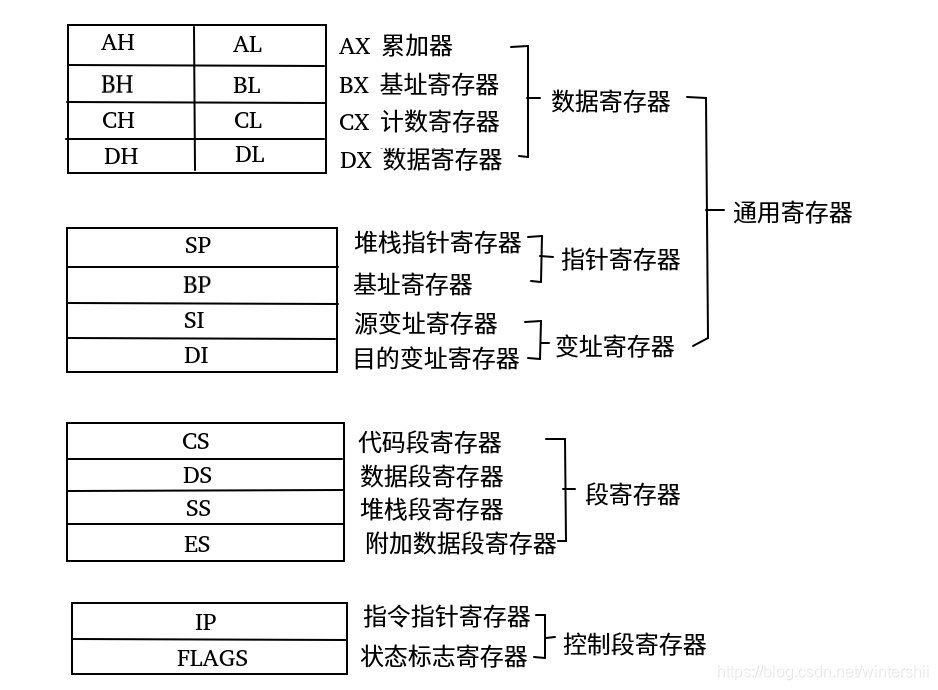
作用:主要作为算数运算、暂存数据以及传递参数,其中rax\rbx\rcx\rdx\rdi是基础通用寄存器、rdi\rsi\r8-r15是扩展寄存器 当调用函数时,前6个参数通常不会放在栈上,而是直接塞进指定的寄存器中,传递顺序:rdi>rsi>rdx>rcx>r8>r9
指令指针寄存器
作用:指向下一条将要执行的机器指令的地址
pwn的最终目的就是为了劫持rip,控制了rip,就可以按照想要的方式进行
而逆向也需要通过观察rip推测下一步的行为
段寄存器
段寄存器有这几个:ES、CS、SS、DS、FS、GS、LDTR、TR,它们各有自己特殊的用途。
在经典的 x86 架构中,最常用的段寄存器有以下 6 个:
- CS (Code Segment):代码段寄存器。存放当前正在执行的程序代码所在的内存段。
- DS (Data Segment):数据段寄存器。存放程序当前处理的静态或全局数据。
- SS (Stack Segment):堆栈段寄存器。存放程序执行时使用的栈空间,用于存储局部变量和函数调用信息。
- ES (Extra Segment):附加段寄存器。通常用于字符串或内存块复制等大型数据传输操作。
- FS / GS:附加数据段寄存器(386之后引入)。没有固定用途,常被现代操作系统(如 Windows 和 Linux)用于存放线程局部存储(TLS)或特定系统数据结构。
不同工作模式下的运行机制
段寄存器在 CPU 的不同工作模式下,其内部存储的内容和寻址方式有着本质区别:
实模式(Real Mode)
在 16 位实模式下(如早期的 8086 CPU),段寄存器直接存放 16 位的段基地址。- 特点:由于地址总线是 20 位,这种“段基址左移 4 位 + 偏移量”的机制可以让 16 位的寄存器访问到 1 MB 的物理内存空间。
保护模式(Protected Mode)
在 32 位和 64 位保护模式下,段寄存器不再直接存放基地址,而是存放一个 16 位的段选择子(Segment Selector)。- 内部结构:段选择子包含 13 位的索引号、1 位的描述符表指示标志(TI)和 2 位的特权级(RPL)。
- 寻址机制:CPU 根据段选择子中的索引,去内存中的全局描述符表(GDT)或局部描述符表(LDT)中查找对应的段描述符(Segment Descriptor)。段描述符中才真正记录了该段的基地址、段界限和访问权限。
- 特点:实现了内存保护和权限分级(Ring 0 - Ring 3),防止应用程序越权访问系统内存。
64位长模式(Long Mode)
在现代 64 位环境下,分段机制被大幅度弱化(平坦模型)。- CS、DS、ES、SS 的基地址被强制硬编码为 0。
- 地址空间不再受分段限制,直接使用 64 位的线性地址(逻辑地址等于线性地址)。
- 例外:FS 和 GS 寄存器仍保留原样,现代操作系统依然用它们来指向特定的内核数据结构(如 Linux 中的每个 CPU 变量,Windows 中的线程环境块 TEB)。
子寄存器
每个 64-bit 寄存器可以进一步划分为更小的子寄存器,分别包含较低位的数据。这些子寄存器的容量分别为 1 字节 8-bits 、2 字节 16-bits 和 4 字节 32-bits 。每个子寄存器都可以独立地被使用和访问,因此当需要处理的数据量较少时,我们无需使用全部的 64 位空间。
子寄存器可以这样访问:
| Size in bits 大小以比特为单位 | Size in bytes 大小以字节为单位 | Name 名称 | Example 示例 |
|---|---|---|---|
16-bit |
2 bytes |
the base name 基本名称 | ax |
8-bit |
1 bytes |
base name and/or ends with l 基本名称以 l 结尾 |
al |
32-bit |
4 bytes |
base name + starts with the e prefix 基础名称加上以 e 开头的前缀 |
eax |
64-bit |
8 bytes |
base name + starts with the r prefix 基础名称加上以 r 开头的前缀 |
rax |
内存地址
如前所述,x86 64 位处理器的地址范围是 64 位宽,从 0x0 到 0xffffffffffffffff 。因此,我们预计这些地址应该位于这个范围内。不过,内存被划分为多个区域,比如堆栈、堆区,以及其他由程序和内核使用的区域。每个内存区域都有特定的 read 、 write 、 execute 权限,这些权限决定了我们可以对其进行读写操作,或者调用其中的地址。